コントラストとフォントを変更
1 年ほど視力障害を経験した を偶然読んだ。
駄文を書き散らすブログでも最低限のことはやろうと CSS をすこしいじった。まだ一部見づらいかもしれないし、他のアクセシビリティ対応は何もできていないけど、何もしないよりいいかな、と。

仕事終わりの散歩も闇夜につつまれるようになってきた。
Tracy Profiler ZoneScoped in Rust
Tracy is a feature rich, frame-oriented profiler which is very useful for developing games and emulators. I’ve been using the profiler for my Famicom/NES emulator written in Rust.
Tracy provides C++ and C APIs so it’s fairly easy to create Rust bindings for most of them. An exception is the ZoneScoped macro which automatically records function name and source location. It’s not trivial to create an equivalent in Rust because it relies on both RAII and C/C++ predefined macros such as __LINE__. I’ve been trying to figure out ways to create an equivalent in Rust because I think the macro is the most useful API of Tracy.
My current approach is to use procedural macros combined with a struct that implements Drop. The struct ties up ___tracy_emit_zone_begin() in the constructor and ___tracy_emit_zone_end() in the destructor. A procedural macro injects code that creates the struct at the beginning of the annotated function. In this approach, the following code:
#[rustracy::zone_scoped]
fn execute_frame(engine: &mut Engine) {
// …
}
will produce something like the below:
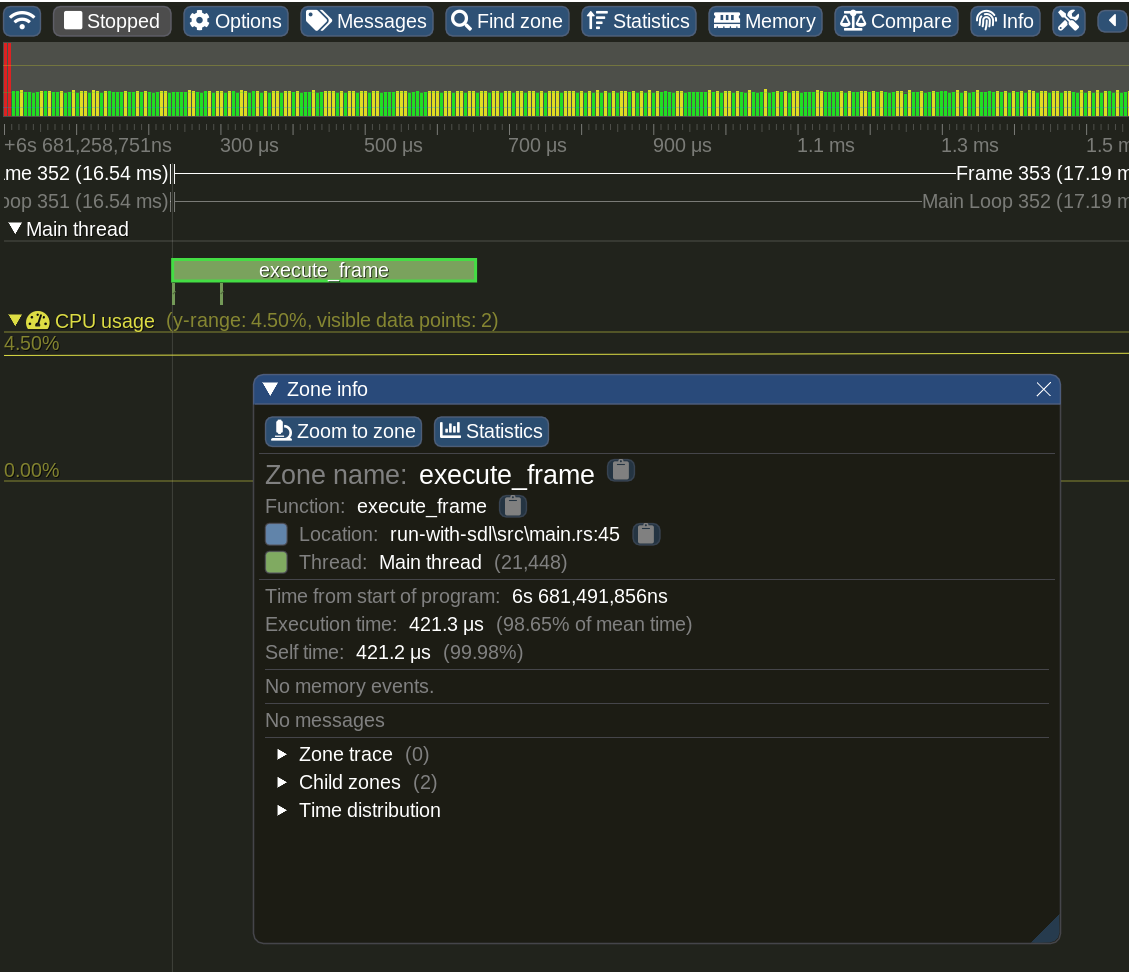
Note that zone name and location are recorded automatically.
A major problem of the approach is that it can’t automatically generate struct/trait names. The following code:
impl Engine {
#[rustracy::zone_scoped]
fn execute_frame(&mut self) {
// …
}
}
doesn’t generate zone name Engine::execute_frame() but generates execute_frame(). I added another producedral macro that takes a “prefix” to work around the problem, but I don’t like the workaround.
You can find my current approach at GitHub.
母校に寄付した
今年も母校の大学院に学生支援の寄付をした。寄付を始めて 3 年目になる。

1 番の理由は控除を受けるため。でも他にも理由がある。まずは自分自身が学費を工面するのに苦労したこと。そして自分は幸運にもいろんな支援をもらって学位を取れたことに感謝していること。高専から(就職を経て)専攻科、大学院といった高等教育にかかる費用は奨学金や政策支援、そして自分で稼いたお金で賄った。受けた恩をほそぼそと返しているつもり。
教育は格差を是正する優れた手段だと思う。今の自分が平均以上の収入を得られているのは、高度な教育を受ける機会に恵まれたからだ。その機会を得られたのは人並み以上に努力したこと、めぐり合わせの運の両方が作用している。
今年は BLM を契機に格差について考える機会がありその思いをより強くした。この思いは良質な教育を受ける機会に恵まれた人には分からないんじゃないかという諦観の念がある。教育格差による優位を意識する機会のない人に、運に恵まれた、という意識が芽生えることはない。能力に見合った対価をもらっている。たぶんそう思っている。そう思うのは当然だし何の問題もない。でも一方でスタート地点でついていた差をどのぐらい意識できているんだろうか、とも思ってしまう。職場での雑談や同僚のツイートから感じる疎外感はここからきている。
とはいうものの、自分は志が高いわけではないし、この違和感について真剣に悩んでいるわけでもない。節税をするにしても、一部はふるさと納税とかを使って自分の生活を豊かにしつつ、一部はちょっとした信条に基づいて寄付するのがいい塩梅かなと思う。
ポッドキャストを聴く日々
朝の散歩中に Misreading #83を、仕事を終えた後の散歩中に Retro Game Audio ep 21 を聴いた。
DTrace が使われている現役 OS といえば MacOS ではないかと思ったけど Mojave でサポートされなくなった、という言及を見つけた。あと、BPF は古の tcpdump のカーネル側の実装を指していて、汎用 Tracing 機構となった実装は eBPF と呼ぶ認識がまだ自分にはあって、色々キャッチアップができていないな、と実感する回であった。
Retro Game Audio の方は少し前に聴き始めて興味のある回をつまみ食いしている。DPCM とコントローラの read が干渉するのは知らなかった。スーパーマリオ 3 がコントローラの read を 3 回やって操作性を担保しているとか、悪魔城伝説のダメージをくらった時の「うっ」っていう効果音を鳴らしている間にキャラクターを操作できないのは干渉を workaround しているんだと思う、とかトリビアがあって面白い。燃えろプロ野球がサウンド再生の観点から面白いとか思いもよらなかった。 Jaleco ってどう発音するんだろう、とか英語話者ならではの疑問も新鮮だった。
Snacking
Snacking なる言い回しを知った。
https://staffeng.com/guides/work-on-what-matters
簡単にできる、でも重要じゃないことをやるのは避けよう、と。やった気になるけど本質的な問題を解いてないよ、と指摘している。耳が痛い。Snacking を encourage する仕組みがあるのも問題。CL/Commit 数を報告させるとか、Github で草を生やすとか。
自分は Preener でもある。自己顕示欲が強いというのとちょっと違うけど、大したことしていないのに人からよく見られたい欲があるというか。文章を書いていて言い回しに凝りがちなのはその表れだと思う。
概念に名前を付けることで意識が向き、改善しようとする姿勢が生まれるので、名前を付けるの大事だなと再認識した。
自己啓発的な記事を紹介するだけのこのブログエントリも Snaking である。
今日もポッドキャスト消化
早速新しいエピソードが出ていたので Misreading chat #82 拝聴。
今回は教養番組みたいなノリで聴けてこういう話題も良い。物理や化学、光学が分かるともっと楽しめるんだろうな。書いたコードがガラスに書かれて北極に埋まっていたら胸熱だなー。
Windows IME の変換アルゴリズムが変わった?意図しない変換が多くなった気がする。
Misreading chat #81 を聞いた
Misreading chat が再開された。めでたい。
強連結成分とりだしてトポロジカルソート、とかいかにもアルゴリズムの授業でありそう、とか思って聞いていたら正にそういう感想を話されていた。
マイナーな SoC でもカーネルツリーからコンパイルすることなく動く perf 的な not-perf というプロファイラをちょっと前に使っていたのだけど、これどうやって動いているんだろう、後で調べようと思って結局調べていないことを思い出した。
追記 (2020-10-06): 森田さんに perf_event_open を使ってあとは自力で頑張っているっぽい、ということを教えてもらった。ありがとうございます。
プロファイラの話題、続編があるといいなあ。最近趣味プロジェクトでプロファイリングをしているので興味がある。
サイトのデザインを少し変更
もうすっかり秋だ。外を歩いていると金木犀の香りが風に乗ってやってくる。爽やか。
観測範囲内でブログへの回帰が進んでいる。このサイトでももうちょっと気軽に、わりとどうでもいいことを日記風につけるのも悪くないかと思い始めた。これまでのトップページはエントリごとにリンクがあって、日記的に運用するのとは相性が悪い。ということで適当に Pagination して最新のエントリを表示するようにした。あとはアナリティクスの利用も明示するように。
ちなみにこのサイトは Hugo で生成して Netlify で運用している。最初は Github pages で運用していたが Netlify だとデプロイが簡単なので気に入っている。ロードはやや遅く感じるけど、速度は重要ではないから特に困ってはいない。
Minimp3 Wasm Without Emscripten
I created a web-based mp3 decoder using minimp3. The decoder is a tiny WebAssembly compiled with clang version 9 (without Emscripten). Applying wasm-opt, the binary size of the decoder is just 21 KB.
Here is a demo page and the repository.
This article describes how I created the decoder.
minimp3 has very few dependencies. It just requires memcpy(3), memmove(3), and memset(3). We can easily find naive implementations of these functions on the Web.
An interesting part is memory allocation. To decode a mp3, we need to pass the mp3 data to minimp3 and allocate memory for decoded PCM data. Both require dynamic memory allocations.
One might think of using malloc(3). This is the way I took first, but after reading Surma’s article that describes wasm-ld’s memory layout, I came up an idea – having a fixed memory layout and allowing dynamic memory allocation only for input (MP3 data) and output (PCM data). This approach reduced most of the complexities of memory allocation. I no longer needed a generic malloc(3) implementation. That eliminated the need for Emscripten.
Here is the memory layout.
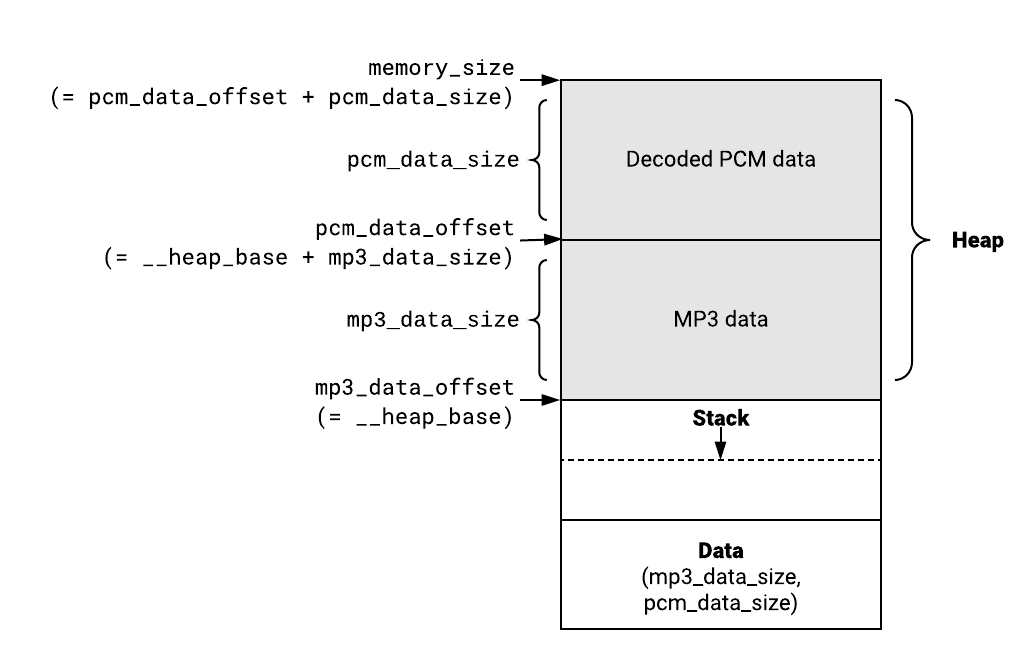
We put input MP3 data at the beginning of the heap (that is, __heap_base). The size of the input MP3 data is stored in mp3_data_size. Decoded PCM data follows it and its size is stored in pcm_data_size. Assuming that the Wasm is used from a single thread, the decoder information such as minimp3’s context (mp3dec_t), number of samples etc are placed on statically allocated memory.
This memory layout doesn’t allow us to free up input MP3 data after decoding. This is a trade-off not having a generic memory allocator. Practically this wouldn’t be a problem because we need to allocate memory for PCM data before decoding and WebAssembly doesn’t provide a way to shrink memory. If we want to free up input data, what we can do is to copy the decoded PCM data somewhere and discard the Wasm instance.
With this memory layout, decoding a MP3 data would look like the below:
// decoder.js
const { instance } = await WebAssembly.instantiate(...);
const wasm = instance.exports;
const mp3Data = /* Some Uint8Array */;
// Set MP3 data into Wasm memory.
wasm.set_mp3_data_size(mp3Data.byteLength);
const mp3DataInWasm = new Uint8Array(
wasm.memory.buffer,
wasm.mp3_data_offset(),
wasm.mp3_data_size());
mp3DataInWasm.set(mp3Data);
// Decode.
wasm.decode();
const pcm = new Int16Array(
wasm.memory.buffer,
wasm.pcm_data_offset(),
wasm.pcm_data_size() / 2);
// Use `pcm`.
// decoder.c
extern unsigned char __heap_base; // Defined by LLVM.
static size_t mp3_data_size;
static size_t pcm_data_size;
const uint8_t *mp3_data_offset() {
return &__heap_base;
}
size_t mp3_data_size() {
return mp3_data_size;
}
void set_mp3_data_size(size_t size) {
mp3_data_size = size;
// Grow memory if needed to set MP3 data.
}
const uint8_t *pcm_data_offset() {
return mp3_data_offset() + mp3_data_size;
}
size_t pcm_data_size() {
return pcm_data_size;
}
void decode() {
pcm_data_size = /* Compute PCM size using minimp3 */;
// Grow memory if needed for PCM data.
const uint8_t *mp3 = mp3_data_offset();
const int16_t *pcm = pcm_data_offset();
// Decode `mp3` using minimp3 and put samples into `pcm`.
}
A tricky part is to use wasm-ld’s __heap_base. By specifying a linker option -Wl,--export-all I was able to use __heap_base in my code, but the option also exported functions which weren’t needed, bloating Wasm binary size slightly.
What I needed was -Wl,--export=__heap_base. --export is a lld’s option which isn’t specific to WebAssembly and that’s why it isn’t listed on the document of wasm-ld.
The remaining parts of the implementation aren’t specific to Wasm. The github repository has the full implementation.
Side notes
We don’t need a custom MP3 decoder if we don’t need to decode large MP3 files. BaseAudioContext.decodeAudioData() is enough for most MP3 files, but decodeAudioData() didn’t work well for my use case. I want to decode large MP3 files like ATP podcast. Decoding such MP3 files consumes a lot of memory which I want to avoid.
WebCodecs may eliminate the demand of this kind of decoder. This is one of APIs I’d like browsers to implement.
黄昏
今の住処は見晴らしがよい。
カタカタとキーボードを叩いていると部屋が暗くなってきて、あ、もう夕方だ、と気づいて窓に視線を送る。夕陽はもうビルの向こう。紅色から蒼色へのグラデーションに魅了され、寒さが堪えるけれど窓を開ける。
冬の澄んだ空気に触れた。はっと子供のころに住んでいた家を思い出す。
雪は降らないけれど早朝には霜が降りる。安普請な家だったから冷え性の自分には堪えた。
近くには電車の駅があった。駅から聞こえてくる笛の音で目が覚めたのを思い出す。冬の時期には良く通る音だった。
身震いしつつそんなことを懐かしむ。