2019年の振り返り
今年はアウトプットを重視した年だった。取り組み始めたら投げ出さずに区切りのいいところまでやる。ある程度達成できたと思う。その一方で集中して取り組まないと解けない問題は避けてしまった印象がある。
趣味プロジェクトを区切りのいいところまで終わらせる、そしてそれらを持続させることを意識した。機能したと思う。以下今年やれたこと。
- 勉強がてら自分に特化した英語辞書アプリを Rust で書き直して普段使いできるレベルまで作った。
- Chrome Mojo IDL の Language Server Protocolを実装した。
- フォントフォーマット変換 Web App をメンテした。
- NES エミュレータをマリオが動くくらいまでは実装した。
特に年末に自由に使える時間があったのが有難かった。やりたいと思っていたことを消化できた。
- 仕事の優先度を考えると手を出しづらかったが余暇としてやれたらいいな、と思っていたことができた。
- アドベントカレンダーに参加できた。
- 私的に頼まれたツールを二つぐらい作れた。
公開しない前提で日記をつけるようにようにした。森田さんのやり方を真似させてもらった。日々の振り返りをする上でこれもいい感じに働いたと思う。その分、ブログを書く意欲がなくなってしまったが、これは妥当なトレードオフだと思う。余談: 森田さんの昨今の記録が公開されていてうれしい。
leetcode は 2, 3 問解いただけでほとんどやらなかった。試験対策に対する興味が失われた…というのは易いけど地頭を鍛えるのを怠ったというのが実情だろう。
英語について。昨年から英会話のレッスンに通ったことでだいぶん苦手意識がなくなった。コードを書いていてもコメントを書くのに労力がいらなくなったのは大きい。喫緊の案件ではなくなったせいで今年はさぼりがちであり、オフィス移転もあって後半はレッスンに通うのをやめてしまった。デザインドキュメントを書くのには相変わらず苦労しているので引き続き改善点のひとつではある。
やりたかったけど時間を割かなかった趣味もある。自分の優先度は「晩酌»»コーディング>(越えられない壁)>その他の趣味」 なので毎晩のように酩酊しつつコードを書いていると時間が溶けてしまう。ある程度しょうがないと割り切っているが来年は読書の時間を増やしたい。
今年聞き始めたポッドキャストで一番気に入ったのが IGN Japan のしゃべりすぎゲーマー。聞き始めのころは「なんだこのイキリオタクは…」とか思っていた今井さんという方がいるのだが、今ではすっかりファンになってしまって配信の時に居ないとちょっとがっかりしてしまう。他の語り手も本当に魅力的で毎回楽しみにしている。
今年使ってよかったものは Windows Terminal と VS Code Remote Development の二つ。特にターミナルは Windows で開発する上での一番の pain point を解消してくれた。マイクロソフトが開発ツールに本気を出すとやっぱりすごいなあという印象を新たにしたし、Mac が微妙すぎるのもあって最近はもっぱら Windows ばかり使っている。
入力と出力、あるいは抽象と具現の車輪を回す。どちらを欠いても物事の理解は進まない。今年は具現に時間を割いていろんなことを達成した感はあるが、出がらしの茶葉になった気分もある。行動指針の粒度を細かくして年単位じゃなく四半期ぐらいのスパンで両輪を回すのもいいかもしれない。
Running Wasm on V8 Without JS API
V8 を wasm の実行環境として C++ アプリケーションに組み込んでみよう。
今回使う V8 のバージョンは 7.8.58。samples/hello-world.cc に wasm を実行する例があるけれど、この例は JS 上に定義された API を叩くスクリプトを実行する、という体で書かれている。V8 としては JS から使う前提があるからこういう例になっているのだろうけど、JS を使わずに wasm を実行できないだろうか。
検索すると stackoverflow に同じ思いの先人が質問していて、回答を元にコードを例示してくれていた。ありがたい。ただいくつか API の変更があったようで、v7.8.58 では動かない。V8 の変更履歴を参照しつつ改変したら動くようになった。これで JS スクリプトを経由せずに wasm を実行できるようになった。が、依然として JS API 自体には依存しており処理が減っている感じがしない。
さらに言えば前処理と後処理が冗長なのはいいとしても、値の引き回しに v8::Local<T> を使わないといけないのも釈然としない。今回は JS を使わないのだから、C++ の数値を V8 JS value に変換し、さらにそれから JS value を wasm の数値型に変換する、といったステップを踏むのは無駄に感じる。C++ ⇔ wasm の型変換があればいい。
そう思いつつ V8 のコードを読んでいると c-api.cc というファイルが目についた。冒頭のコメントによると、仕様への提案をベースに書かれたものらしい。wasm を C/C++ に組み込むための提案、だそう。これが求めていたものっぽい。
使い方を調べてみよう。V8 は Wasm C API を third_party/wasm-api 配下に組み込んでいる。V8 を組み込む C++アプリケーションはthird_party/wasm-api/wasm.hhをインクルードすることで wasm の関数の引数や戻り値を v8::Local<T> を使うことなくやりとりできるようになる。提案の例を見れば使い方はつかめると思う。要点を抜粋すると以下のような感じ。
wasm::vec<byte_t> binary; // wasm バイナリ、外部からの入力
// 実行環境の初期化
auto engine = wasm::Engine::make();
auto store_ = wasm::Store::make(engine.get());
auto store = store_.get();
// コンパイルとインスタンス生成
auto module = wasm::Module::make(store, binary);
auto instance = wasm::Instance::make(store, module.get(), nullptr);
// 関数の取り出し
auto exports = instance->exports();
assert(exports.size() == 1 && exports[0]->kind == wasm::EXTERN_FUNC && exports[0]->func());
auto run_func = exports[0]->func();
// 実行
wasm::Val args[] = { wasm::Val::i32(14), wasm::Val::i32(9) };
wasm::Val results[1];
run_func->call(args, results);
printf("%d\n", results[0].i32());
(コード全体はここを参照)
V8 API を使った例に比べるとだいぶんすっきりとする。ただ内部ではv8::Contextやらv8::Isolateなんかを使っているので初期化等にかかる時間はたぶん大差がない。
一方、関数呼び出しの引数と戻り値に関しては V8 JS value への変換がなくなっており、この部分は高速化が見込めるんじゃないだろうか。
今回は V8 を使うのを前提としたけれど、実際のところ wasm を実行したいだけであれば Wasmer を使う、あるいは WASI に則った実行環境を使うほうが良い。JS のオーバヘッドが気になるなら JS をサポートしてない環境を使うのが理にかなっている。
wasm: Copy と Anyref Export の速度比較
AssemblyScript でライブラリコードの高速化をしてみる の Appendix で anyref を使うとコピーのオーバーヘッドを減らせるかもしれないとの記述があった。おおなるほどそうかも、と思ったが少し考えてみると別のオーバーヘッドが生じそうだ。メモリアクセスをエクスポートされた関数呼び出しに変える必要がある。エクスポートされた関数の呼び出しはインライン化できないし、JS <-> wasm の型変換も必要になる。
ということでどちらが早いのかを 2019 年 7 月時点での評価をしてみようと思う。現時点で anyref が使えるのは Firefox nightly と Chrome。Chrome では --js-flags=--experimental-wasm-anyref フラグを渡す必要がある。
やりたいことと比較する対象を整理する。なんらかのデータを JS 側で Uint8Array として保持している。このデータを wasm で効率的に処理したい。比較する手段は次の二つ。
- Copy: wasm モジュールのメモリ領域にデータをコピーする。
- Export: データにアクセスする関数を
anyrefを使ってエクスポートする。
1 は従来のやり方。 JS 側で持っているデータを wasm の メモリ領域にコピーして、コピー先のアドレスとデータの長さを wasm で定義した関数に渡す。2 は冒頭のスライドに書いてあるやり方。anyref があればデータへアクセスする関数を軽量に wasm モジュールに提供できるのでは、というアイデアだ。JS にある Uint8Array buf に対して、 buf[offset] と同等の関数 readByteFromUint8Array(arr: anyref, offset: i32): i32 を wasm モジュールにエクスポートする。
それぞれのオーバーヘッドをみるために Uint8Array の各バイトを足し合わせる単純な関数を wasm で定義する。C で書くとこんなふうなやつ。
/* Copy を使った関数 */
int32_t accumulateCopy(uint8_t *arr, int32_t length) {
int32_t sum = 0;
for (int32_t i = 0; i < length; i++) {
sum += arr[i];
}
return sum;
}
/* Anyref を使った関数 */
extern struct Uint8Array;
extern uint8_t readByteFromUint8Array(Uint8Array *arr, int32_t length);
int32_t accumulateAnyref(Uint8Array *arr, int32_t length) {
int32_t sum = 0;
for (int32_t i = 0; i < length; i++) {
sum += readByteFromUint8Array(arr, i);
}
return sum;
}
現時点では anyref を出力する安定したコンパイラがないので今回は上記の関数を wat で手書きした。
この 2 つの関数の実行にかかる時間をデータのサイズ毎に計測する。データサイズを 1K, 1M, 10M とした時に手元の Chrome でかかった時間(ミリ秒)のグラフを以下に示す。横軸は対数。
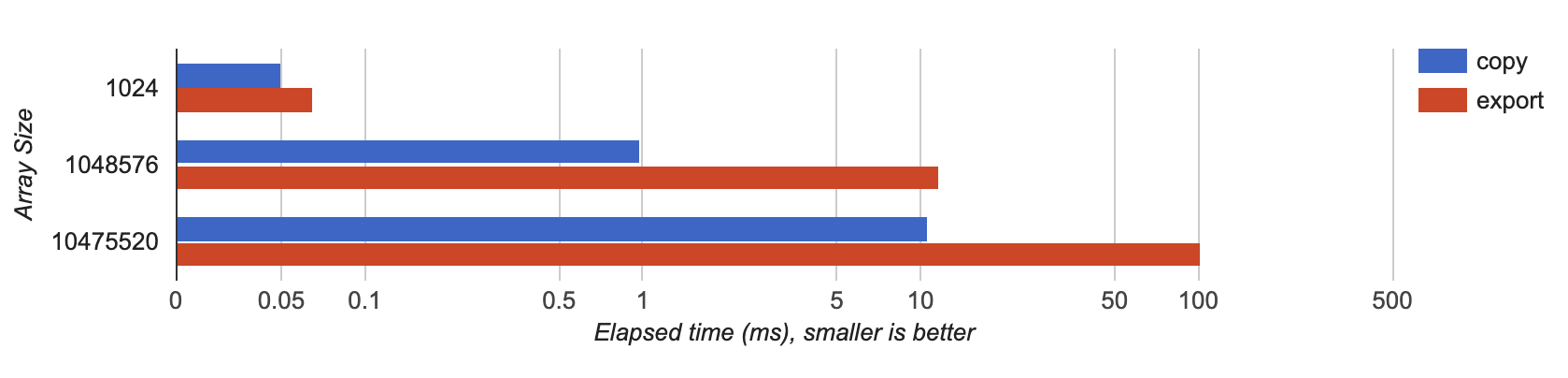
複数回試してみたところ、手元の環境ではデータサイズが 1K の場合は大差ないが、大きいデータサイズではコピーするほうが常に 10 倍ぐらい速い、という結果になった。Firefox でも傾向は同じ。多分どの環境でも似たような結果がでるんじゃないかと思う。使ったベンチマークはここに置いた。
結果を簡単に考察すると: anyref を使ってエクスポートした関数を用意するとコピーにかかる時間は省略できるが、別のオーバーヘッド、すなわち wasm と JS を行き来するコストが支配的かつコピーよりも遅い。TypedArray とそのメソッドを JS を経由せずに wasm から直接呼び出せて、かつその呼び出しをインライン化できないと anyref を使っても速度の向上は見込めなさそう。
Tweaking site design
Nord のカラーパレットが気に入ったので使わせてもらおう。pygments のスタイルも合うように変更する。
柔らかい感じの見た目にしたいので border-radius で枠を少し丸くするように変更。あと line-height も調整した。少し行間がある方が読みやすく感じる。
Rust: Raspberry Pi (Raspbian) 向けの実行バイナリを手軽に作る
Rust で書いたアプリケーションを手元の Raspberry Pi 3 で動かしたい。ベアメタルではなくて OS は Raspbian。
まずは raspi 上でコンパイルしてみる。遅い。自分のアプリをコンパイルするのに 60 分 (!) もかかる。アプリの開発自体は PC でやっているからそんなに頻繁に raspi 用のバイナリを作る必要はないのだけど、さすがにこれではやっていられない。
raspi 上でバイナリを作るのは諦めてクロスコンパイル環境を用意する。Rust は簡単にいろんなアーキテクチャ向けの toolchain 入れられるものの、コンパイルだけでなく Raspbian 向けの実行バイナリをリンクするには GCC のクロスコンパイラ (gcc-arm-linux-gnueabihf) が別途必要になる。開発しているマシンの OS に対する依存が少なく、かつ手軽にリンクまでできる環境を作りたい。となると Docker コンテナでクロスコンパイル環境を作れば良さそうだ。
まずは toolchain のセットアップから。DockerHub に Rust の公式イメージがあるのでこれをベースにする。加えて GCC のクロスコンパイラと Rust のarmv7-unknown-linux-gnueabihf向け toolchain をインストールする。コンテナが起動したら cargo build するようにしておく。Dockerfile はこんな感じ。
FROM rust:1.35
# コンテナ実行時に -v オプションでマウントされるのを前提としている。
WORKDIR /usr/src/myapp
RUN apt-get update && apt-get install -y gcc-arm-linux-gnueabihf
RUN rustup target add armv7-unknown-linux-gnueabihf
CMD ["cargo", "build", "--target", "armv7-unknown-linux-gnueabihf", "--release"]
続いて Rust で書いたアプリのリポジトリ配下の.cargo/configにクロスコンパイル用の設定を書いておく。
[target.armv7-unknown-linux-gnueabihf]
linker = "arm-linux-gnueabihf-gcc"
あとは Docker イメージ作って実行すれば raspi 上で動くバイナリを生成できる。
$ docker build -t myapp-cross-raspi
$ docker run -it -v "$PWD":/usr/src/myapp myapp-cross-raspi
$ file target/armv7-unknown-linux-gnueabihf/release/myapp
target/armv7-unknown-linux-gnueabihf/release/myapp: ELF 32-bit LSB shared object, ARM, EABI5 version 1 (SYSV),
...
ただ、上記の設定だけではcargoのキャッシュがコンテナ内に保持されてしまう。つまりコンテナを作り直すたびに myapp が依存している crates をダウンロードするはめになる。これは資源の無駄なので自分は CARGO_HOME 環境変数を上書きしてホストの適当な場所を指すようにしている。
$ docker run -it -v "$PWD":/usr/src/myapp -e CARGO_HOME="$PWD"/.docker-cargo myapp-cross-raspi
補記
Docker Desktop (Windows と Mac) では最近になって Arm アーキテクチャのコンテナを x86 環境でも動かせるようになったらしい。
Building Multi-Arch Images for Arm and x86 with Docker Desktop - Docker Engineering Blog
つまり Windows と Mac ではコマンド一つ叩くだけで Rasbian 上で動くバイナリをクロスコンパイルできる。
$ docker run -it -v "$PWD":/usr/src/myapp -w /usr/src/myapp arm32v7/rust:1.35 cargo build
こっちのほうが楽だ、と一瞬思ったが、これが結構遅い。内部で QEMU 使っているようだから遅いのはしょうがない気がするが、actix-web を使った単純な hello-world でも手元のマシンで 10 分ぐらいコンパイルに時間がかかった。
参考
梅雨入り前の一日
風鈴がちりん、となった。我が家には風鈴があるのであった。
たしか川崎大社で買い求めたものだ。存在を忘れていたが風情があって良い。
午後にかけてよく晴れた日。ふらっと散歩をして気を良くした。
WebAssemblyのanyref
WebAssembly にreference typesがあるとどううれしいのか、を理解しようとして書いたメモ。参照型として二つ提案されているが、ここではanyrefに着目する。
(注: Reference types は提案段階なので各種ブラウザではまだデフォルトで有効にはなっていない。Chrome で試すにはコマンドライン引数に--js-flags=--experimental-wasm-anyrefをつける必要がある。)
任意の JS の値を受け取って、それをそのまま返すidentity()という関数を wasm で作ろう。とってつけた例題だけど骨子を最小限のコードで示すために許してほしい。こういうやつ。
identity(value) === value; // => true
anyrefが存在しない現在の仕様だとこれは wasm だけでは定義できない。なぜなら wasm の関数は引数/戻り値に整数型か浮動小数点型しか指定できないから。JS には数値以外にも文字列型やオブジェクト型がある。文字列やオブジェクトを数値に変換する仕組みが JS 側に必要だ。
任意の JS の値を数値に変換する単純な方法としてぱっと思いつくのは、グローバルな配列をひとつ用意して、そこを値の格納先として使うやり方だろう。JS/wasm 間での値の受け渡しはこの配列のインデックスを使う。要はヒープみたいなもの。必要最小限の実装はこんな感じ。
let heap = [];
function toWasmValue(value) {
heap.push(value);
return heap.length - 1;
}
function fromWasmValue(index) {
return heap[index];
}
Wasm の関数を呼ぶときの流れは、toWasmValue()でインデックスを取得、wasm で定義された関数の呼び出し、戻り値をfromWasmValue()で JS の値に戻す、という感じになる。
(async function() {
const stream = fetch("identity.wasm");
const { instance } = await WebAssembly.instantiateStreaming(stream);
// Wrapper function of `identity`
function identity(value) {
const index = toWasmValue(value);
const ret = instance.exports.identity(index);
return fromWasmValue(ret);
}
console.log(identity(42)); // => 42
console.log(identity(window)); // => window
})();
Wasm 側のコードはただ受け取ったインデックスを返すだけ。
(module
(func (export "identity") (param i32) (result i32)
;; Just return the argument
get_local 0))
これでidentity()を定義できたが、値を単純に JS → wasm → JS と引き回したいだけなのになんだか面倒だ。しかも今の実装は実用に耐えない。toWasmValue()を呼ぶたびにヒープが大きくなるし、オブジェクトへの参照が消えないのでリークが起きる。きちんと使えるものを作ろうと思うと、不要になった値をヒープから削除しなければならないし、必要に応じてフラグメンテーションも解消しないといけない。
要はメモリ管理が必要になるのだけど、GC がある JS の上にメモリ管理機構を作るのは冗長だと思える。wasm 側で値を操作しないなら(単純に JS に引き渡すだけなら)、その値への参照を wasm に渡すのを許可してもいいのではないか。そうすれば値の生存期間の管理は JS 側の GC に任せられるし、値の変換も不要になる。
…こんな感じでanyrefが提案されたんだろう、と自分は理解した。
実際にanyrefを使って書き直すと以下のようにだいぶすっきりする。JS 上にヒープを作る必要はない。JS 側の GC が参照の生存管理をする。
(async function() {
const stream = fetch("identity_anyref.wasm");
const { instance } = await WebAssembly.instantiateStreaming(stream);
console.log(instance.exports.identity(42)); // => 42
console.log(instance.exports.identity(window)); // => window
})();
Wasm 側のコードは引数と戻り値の型を変えるだけ。wat2wasmで以下をコンパイルするときは--enable-reference-typesフラグをつける。
(module
(func (export "identity") (param anyref) (result anyref)
;; Just return the argument
get_local 0))
anyrefが解きたい課題は分かった。では実際の問題に対してanyrefはどううれしいのか。多分ほとんどの開発者には特段メリットはないんじゃないか。というのも、こういう低レイヤの変換やメモリ管理はすでに Emscripten や wasm-bindgen が面倒を見てくれているから。これらのフレームワーク自体にとってはanyrefがあるとラッパー関数なんかを削減できてうれしいと思う。開発者にとってもランタイムのサイズが減って間接的にうれしいかもしれない。
提案の概要にはここで説明した以外の動機も書いてある。むしろ主眼はそちらかもしれなくて、reference types はほかの提案の土台としての側面が強そう。
補記
anyrefはWebAssembly.Globalの型やWebAssembly.Tableの要素型としても指定できる。
参考
再帰的なデータ構造のイテレータを手書きする
amos.me - Recursive iterators in Rust が面白かった。以前 AST をたどるイテレータを書いたときに同じような問題に遭遇した記憶がある。そのときは既存のイテレータやアダプタを組み合わせてうまい具合にやる方法が思いつかず、結局自分でイテレータを実装した。イテレータの内部では状態を管理する列挙型と、今どのノードをたどっているのかを記憶するスタックを使用する。
上記のエントリで出てくる例題に対して実装するとこんなかんじ → Rust Playground
うまく既存のイテレータやアダプタを使って関数型言語っぽい書き方をできるようになりたいなあと思う一方、自分にはどうも手続き的なコードのほうが理解しやすい。イテレータを組み合わせて書いてあるコードはすっきりしていて賢いと思うんだけど、理解が追いつかないことが多い。Rustを使い始めてそこそこ経つので慣れの問題だけじゃないかもしれない。
ニューヨークでベーグルを食べた
4 月に出張でトロントとニューヨークを訪れた。渡航前に引いた風邪を引きずってしまったせいで体調が悪く、しんどい旅となった。
トロントではあまり観光できなかったが、後半少し回復したのでニューヨークを少し観光することができた。ニューヨークを訪れるのは二度目。最初に訪れたときに食べたベーグルが美味しかったので、今回もベーグルを食べようとお店を巡った。
最初に訪れたのは Tompkins Square Bagels。界隈でベストなベーグル屋さんはどこ?と現地の同僚に聞いたら教えてくれたお店である。

ドライトマトが入ったクリームチーズを挟んでもらった。翌日まで顎がつかれるぐらい噛みごたえのある生地で自分好みの食感であった。

別の日にはアッパーウエストサイドにある Aboslute Bagles を訪問した。ここは前回ニューヨークに来たときに一番印象に残っていたので再訪しようと思っていたお店だ。朝 9 時ぐらいについたのだけど、けっこうな行列ができていた。ただ、店内で食べていく人はあまりいないので待ち時間はそれほどでもない。どれを食べようかと悩んでいる間に行列は掃けた。

定番のサーモンが入ったスプレッドにしよう思っていたのだけど、陳列されていたブルーベリーのやつが美味しそうだったので少し悩んだ結果ブルーベリーに変更した。ベーグルはそれに合いそうなプレーンを選択。

これが正解で、とても美味しかった。写真ではわからないかもしれないが、ここのベーグルはかなり大きい。一食分としては半分でも多いくらい。それでも完食してしまった。おかげでこの日はお昼が入らなかった。再度ニューヨークを訪れる機会があればここのベーグルはまた食べたい。
最終日の空港に向かう前に訪れたのはBrooklyn Bagel & Coffee Company。ここではスプレッドを頼まずベーグル単体で購入した。種類はプレーンと全部入り(Everything)。

これは結局食べる余裕がなくて帰国後冷凍保存した。これも一つが大きいので食べごたえがありそうであった。
TypeScriptの型チェックと仲良くする
TypeScript のコンパイルエラーを一時的に抑止したい場面は多々ある。この記事では、自分が型エラーを回避するのに便利だなと思っている機能を状況に応じて 3 つ紹介したいと思う。想定している文脈は、趣味プロジェクトで、フレームワークを使わない素のフロントエンド開発。
Type Guards
状況: このエレメントは<foo>なんだからbarっていう属性があるのに TypsScript はそれを分かってくれない。
例えばオーディオを再生するページを静的に記述したとする。
<audio id="my-audio"></audio>
このオーディオに対して再生位置をリセットするスクリプトを書きたい。書いている側からするとmy-audioはHTMLAudioElementであることが分かっている。getElementById('my-audio')の返り値はHTMLAudioElementだからと思って以下のように書くとコンパイラに怒られる。
const audioEl = document.getElementById("my-audio");
// NG: `[ts] Property 'currentTime' does not exist on type 'HTMLElement'. [2339]`
audioEl.currentTime = 0;
この場合は Type guards に頼る。if 文で型の整合性をチェックすると、コンパイラがコントロールフローを解析して型を限定してくれる。以下では if 文以降audioElはHTMLMediaElementであることが保証される。
const audioEl = document.getElementById("my-audio");
if (!(audioEl instanceof HTMLMediaElement)) {
throw new Error("#my-audio is not an HTMLMediaElement");
}
// OK: At this point TS compiler knows `audioEl` is an HTMLMediaElement.
audioEl.currentTime = 0;
冗長だけど if 文以降に型チェックの恩恵を受けられることを考えるとトレードオフとしては悪くない。asを使う方法もあるけれど、 Type Guards を使ったほうがより安全になる。
参考: Advanced Types · TypeScript
Non Null Assertion Operator
状況: 関数foo()はnullやundefinedじゃない値を返すのが分かってるのに TypeScript がそれを分かってくれない。
2D の絵を描きたいとする。ブラウザ上で 2D の絵を描くにはHTMLCanvasElementを用意してそれに対してgetContext('2d')を呼んで描画コンテキストを取得する。だけど TypeScript はgetContext()はnullを返すかもしれないと文句を言ってくる。
// NG: [ts] Type 'CanvasRenderingContext2D | null' is not assignable to type 'CanvasRenderingContext2D'.
// Type 'null' is not assignable to type 'CanvasRenderingContext2D'. [2322]
const ctx: CanvasRenderingContext2D = canvas.getContext("2d");
この場合は!を末尾につけている。これはNon Null Assertion Operatorというやつで、式の末尾に!をつけるとコンパイラはその式がnullやundefinedを返すことがないと仮定するようになる。nullやundefinedを返す式にしか使えないけど、Type guards を使うよりも簡潔に型を限定できる。
// OK
const ctx: CanvasRenderingContext2D = canvas.getContext("2d")!;
ctx.clearRect(0, 0, width, height);
ただ Type guards と違ってコンパイラが null や undefined にならないことを保証してくれるわけでは無い、という点に注意。
参考: TypeScript 2.0 · TypeScript
@ts-ignore
状況: window に一時的にデバッグ用のプロパティを追加したいけど TypeScript がそれを許してくれない。
開発の初期段階ではブラウザのデベロッパーツールを使っていろんな検証をしたい。例えば自作のAppオブジェクトの状態をデベロッパーツールで確認したいとする。そんなときには手っ取り早くアクセスできるオブジェクト、例えばwindowにそのオブジェクトをぶら下げるのが簡単だろう。でも単純にそれをやろうとするとコンパイラが怒る。
const app = new App(...);
// NG: [ts] Property 'app' does not exist on type 'Window'. [2339]
window.app = app;
こういう状況では@ts-ignoreを使っている。@ts-ignoreをコメントとして書くと、以後の一文だけはコンパイラは何もエラーを出さなくなる。tsconfig.json などで一括にエラーを抑止するのは避けたいけど、この一文だけ見逃して欲しい場面で重宝する。
const app = new App(...);
// @ts-ignore
window.app = app; // OK
...
console.log(window.app); // NG
あくまで@ts-ignoreの直下の行だけエラーを出力しないようになるだけなので、ほかの場所でappを使おうとするとコンパイラに怒られる。自分は@ts-ignoreをDevToolsを使ったデバッグや調査をしたいときや、トリッキーなimportをしている場所のエラーを抑止したいときなんかに使っている。
参考: TypeScript 2.6 · TypeScript
参考文献
Revised Revised 型の国のTypeScript は非常に良い入門書。一日ぐらいかけて目を通しておくと TypeScript の気持ちがわかるようになると思う。自分は技術書典3で紙の本を購入した。
TypeScriptのunsafeな操作まとめ では TypeScript の型検査が常に有効ではないことを議論している。