AssemblyScript でライブラリコードの高速化をしてみる の Appendix で anyref を使うとコピーのオーバーヘッドを減らせるかもしれないとの記述があった。おおなるほどそうかも、と思ったが少し考えてみると別のオーバーヘッドが生じそうだ。メモリアクセスをエクスポートされた関数呼び出しに変える必要がある。エクスポートされた関数の呼び出しはインライン化できないし、JS <-> wasm の型変換も必要になる。
ということでどちらが早いのかを 2019 年 7 月時点での評価をしてみようと思う。現時点で anyref が使えるのは Firefox nightly と Chrome。Chrome では --js-flags=--experimental-wasm-anyref フラグを渡す必要がある。
やりたいことと比較する対象を整理する。なんらかのデータを JS 側で Uint8Array として保持している。このデータを wasm で効率的に処理したい。比較する手段は次の二つ。
- Copy: wasm モジュールのメモリ領域にデータをコピーする。
- Export: データにアクセスする関数を
anyrefを使ってエクスポートする。
1 は従来のやり方。 JS 側で持っているデータを wasm の メモリ領域にコピーして、コピー先のアドレスとデータの長さを wasm で定義した関数に渡す。2 は冒頭のスライドに書いてあるやり方。anyref があればデータへアクセスする関数を軽量に wasm モジュールに提供できるのでは、というアイデアだ。JS にある Uint8Array buf に対して、 buf[offset] と同等の関数 readByteFromUint8Array(arr: anyref, offset: i32): i32 を wasm モジュールにエクスポートする。
それぞれのオーバーヘッドをみるために Uint8Array の各バイトを足し合わせる単純な関数を wasm で定義する。C で書くとこんなふうなやつ。
/* Copy を使った関数 */
int32_t accumulateCopy(uint8_t *arr, int32_t length) {
int32_t sum = 0;
for (int32_t i = 0; i < length; i++) {
sum += arr[i];
}
return sum;
}
/* Anyref を使った関数 */
extern struct Uint8Array;
extern uint8_t readByteFromUint8Array(Uint8Array *arr, int32_t length);
int32_t accumulateAnyref(Uint8Array *arr, int32_t length) {
int32_t sum = 0;
for (int32_t i = 0; i < length; i++) {
sum += readByteFromUint8Array(arr, i);
}
return sum;
}
現時点では anyref を出力する安定したコンパイラがないので今回は上記の関数を wat で手書きした。
この 2 つの関数の実行にかかる時間をデータのサイズ毎に計測する。データサイズを 1K, 1M, 10M とした時に手元の Chrome でかかった時間(ミリ秒)のグラフを以下に示す。横軸は対数。
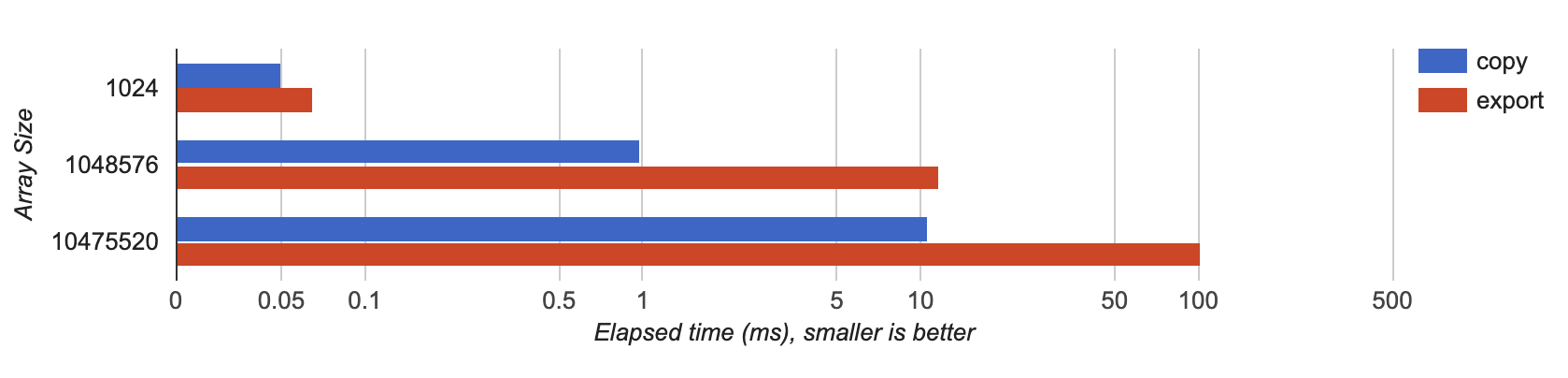
複数回試してみたところ、手元の環境ではデータサイズが 1K の場合は大差ないが、大きいデータサイズではコピーするほうが常に 10 倍ぐらい速い、という結果になった。Firefox でも傾向は同じ。多分どの環境でも似たような結果がでるんじゃないかと思う。使ったベンチマークはここに置いた。
結果を簡単に考察すると: anyref を使ってエクスポートした関数を用意するとコピーにかかる時間は省略できるが、別のオーバーヘッド、すなわち wasm と JS を行き来するコストが支配的かつコピーよりも遅い。TypedArray とそのメソッドを JS を経由せずに wasm から直接呼び出せて、かつその呼び出しをインライン化できないと anyref を使っても速度の向上は見込めなさそう。